在刚刚过去的“双十一”购物狂欢季,阿里云经历了一次大规模故障,导致阿里系产品集体中断服务。11 月12 日,淘宝、钉钉、闲鱼、阿里云盘等阿里系产品出现无法使用的问题, “阿里全系产品崩了” 的话题迅速引发众多关注。此次故障不仅阿里自家的产品受到影响,据天眼查数据,阿里云的企业用户超过 300 万家,这些客户由于云服务不可用,业务运营受到严重影响。
故障的地域范围广泛,覆盖了包括华北、华东、华南、中国香港以及国际地区在内的多个地区。根据阿里云官网的官方通告,故障于 11 月 12 日 17:44 开始被阿里云监控系统检测到,直到 21:11,所有受影响的云产品最终恢复正常,整个事故过程持续了超过 3 个小时。
故障原因猜测
什么样的故障能致使阿里云全线服务不可用,且故障范围覆盖全球各个区域,故障恢复长达 3 个小时?
由于故障涉及到多个机房和区域,不太可能是存储或网络等基础设施的问题,因为这些通常采用多可用区部署。
现象主要表现为:被管控的资源,如云服务器 ECS 和云数据库 RDS,仍然可以继续运行,但用户无法通过控制台或API 进行管理操作。因此极有可能是 Auth 这样的一种全球性的基础服务。
虽然以上分析仅为推测,并不代表确切的故障原因,但不少业内专业也给出了类似的推测:


图片来源:DevOpSec
什么是认证服务?
认证服务(Auth 服务)是一种用于身份认证和授权的基础服务。它在许多系统和应用程序中起着关键作用,确保只有经过授权的用户可以访问受保护的资源和功能。大家常用的以下功能,都属于认证服务的范畴:身份验证、访问控制、用户管理、单点登录(SSO)、安全审计。作为系统的基础安全服务,它是建立安全、可信赖的系统和保护敏感资源的关键组成部分。

如何保证 Auth 服务的 SLA ?
对于如此重要的基础安全服务,其企业相关负责人如何提高企业认证服务的 SLA,避免"全球性故障"?其使用者应该如何评估及挑选优质的认证服务厂商?围绕 "高 SLA (Service Level Agreement)的认证服务",其核心指导思想为:防治结合。
防:在故障真的发生的时候,能及时收到故障通知,采用对应的降级策略,防止由于认证服务不可用造成全线服务不可用的大故障
治:在基础设施层面,保持云中立、保证异地多活、提升系统可观测性,拥抱容器化技术及微服务治理,从而全面提升整个系统的 SLA,避免出现“短板效应”
下面将以 Authing (Authing 就是身份云) 为例,为大家具体讲解“防治结合”的实施落地方案。
防:事件通知驱动 + SDK 快速集成 + 启动降级措施
为帮助认证服务使用方实现 “在故障发生时,能及时收到相关事件,采用降级策略” 这一防御目标,其解题思路为:通过 SDK 方式快速接入认证服务,减少研发成本的同时,通过让 SDK 订阅 Authing 服务端的相关故障事件,及时采取降级措施。
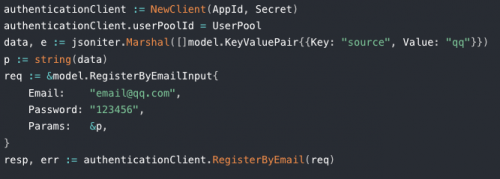
多语言 SDK / API / 认证组件
通过丰富且兼容多种开发语言、多种开发框架的 SDK / API / 认证组件,可让用户 5 行代码快速接入认证服务,让其应用服务具备账号密码认证、短信验证码认证、社交账号登录、企业账号登录、单点登录 SSO、多因素认证 MFA 等安全能力。
事件驱动的云原生身份平台
事件表明状态发生变化,即:某事已经发生。事件用于向相关方发出状态发生变化的信号。在本案例中,事件即为“故障事件”;
Authing 3.0 是以事件驱动(EDA)架构重塑的云原生身份平台,通过事件驱动架构大幅提升了平台的响应速度、可扩展性和开发者体验,并能够实现更加及时的安全事件响应和更加卓越的客户体验。
使用 Authing 的事件相关 SDK,开发者可以订阅 Authing 平台产生的事件,当事件发生时,Authing 服务会实时把事件的类型及当前事件关联的数据以 WebSocket 方式以 JSON 的数据格式主动推送给开发者。也可以在 Authing 控制台添加自定义事件,然后使用事件 SDK 向 Authing 服务推送自定义事件,用来触发特定的工作流程。式将事件内容以 JSON 格式进行推送。


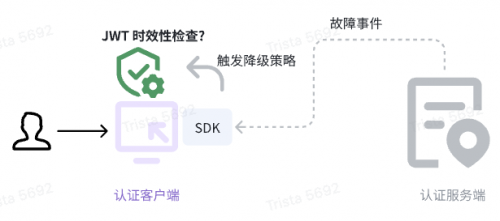
借助事件驱动变化的理念,用户可以订阅“认证服务故障事件”,Authing SDK 在收到该事件后可根据用户的配置和期望方式,实施降级措施,避免全服不可用的故障。
降级措施
降级措施是指在某种情况下,为了保证系统的可用性或确保某项功能的正常运行,采取的临时替代方案或备用方案。当系统或功能遇到问题或无法以预期的方式运行时,降级措施可以帮助系统继续正常运行,但会以降低的性能、功能或安全性为代价。
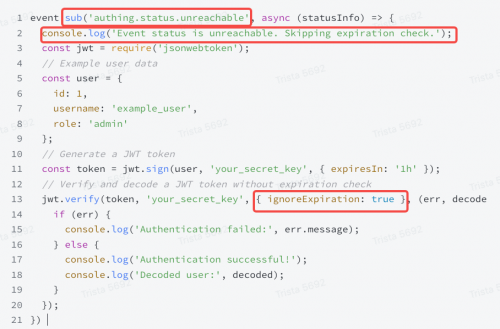
在本案例中,为了能让系统正常运行,将会牺牲较小部分的安全性。其中一种实现方式为:在接收到“故障”事件后,通过忽略本地缓存的认证 Token 的过期时间,持续提供认证能力;待收到“故障恢复”的事件后,再恢复到常规的更安全的认证方式上,即重新申请 Token 并验证 Token 的过期时间。
在主流的认证方式及协议,如 OAuth 2.0、OpenID Connect、单点登录等,都会使用 JWT(JSON Web Token)用于在不同实体之间安全地传输信息。客户端,例如浏览器等,会将 JWT 进行缓存,以便在后续的请求中使用。JWT 会有过期时间,用于指定 JWT 的有效期。在验证 JWT 时,依赖方通过不检查 JWT 的过期时间,持续使用本地缓存的 JWT 来提供认证服务,从而达到降级的目的。
治:云中立 + 异地多活 + 可观测性 + 微服务治理
尽管“防”的手段,可以通过牺牲部分安全性或功能来换取系统可用性,但其治本之道还是需要从基础建设、服务治理、可观测性的角度提升整体认证服务和系统的可用性,从而提升整体的 SLA。
云中立
系统做到云中立,才能保证不被某一朵云厂商绑定,拥有了选择权,促进数据流动和互操作性。一旦出现某一朵云服务故障的时候,可以迅速将流量切到其他云上提供服务,缩短不可用时间。
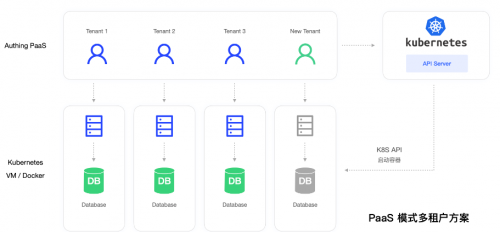
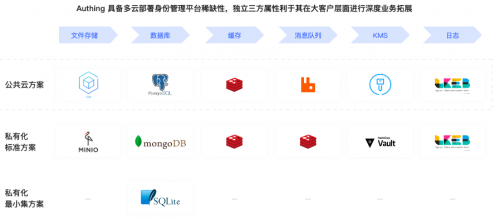
为了让系统做到云中立,应该尽可能使用各个云的通用服务,减少对某一朵云的服务依赖;在设计服务架构时,最大程度去兼容用户私有云、各类公有云的云环境。通过成熟 Kubernetes 容器化技术,使整套服务体系同时支持公共云、混合云和私有云部署,并且达到分钟级别弹性扩容,最大可支持亿级别用户认证访问场景。
Authing 使用 Kubernetes 作为容器编排和管理平台,用于在跨多个主机和集群中自动化部署、运行、编排和管理容器化应用程序。同时在数据存储层面,选择通用标准的数据库、缓存、KMS、消息队列、日志等云服务,并在架构设计时,对各个云服务进行适配,从而达到灵活配置兼容各种云服务、多云部署、故障时能及时切换、系统云中立等目标。其架构如下图所示:
异地多活
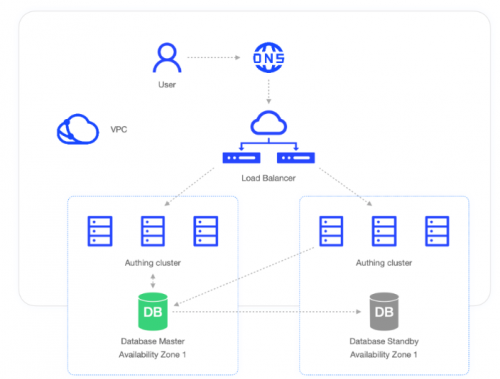
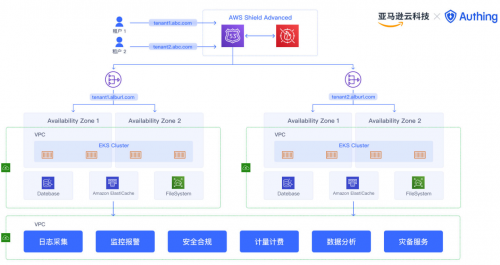
异地多活、多数据中心、两地三中心等,每当提到这些主流措施,其本质在于:增加冗余副本服务,用于在故障发生时,迅速使用副本服务提供系统可用性。地理位置、网络连接、副本个数和复杂性、数据同步复制、数据安全和合规性、SLA 等级、成本等是在设计异地灾备时,要重点考虑和平衡的。
Authing 通过多云部署 + 多 AZ (Available Zone) + 智能 DNS 的方式,实现异地多活、国内外多 Region 部署、故障时自动切流的方式,提升系统整体的可用性和对客户的 SLA。
可观测性
可观测性(Observability)是指在复杂系统中全面了解、理解和监测系统的运行状态、行为和性能的能力。它是一种系统设计和运维的理念,旨在提供对系统内部和外部的可见性,以便快速识别和解决问题,优化性能,并提供对系统行为的深入洞察。
在本案例中上述的“事件通知驱动”从而实施降级措施的基础建设重要部分,即是系统的可观测性。要做的系统的可观测性,需要注重考虑:
1.监测:通过收集、记录和分析系统的指标、日志和事件,实时监测系统的运行状态和行为。
2.日志管理:管理和分析系统的日志数据,以了解系统的运行过程、事件和错误。
3.追踪和分布式跟踪:通过跟踪请求在系统中的流经路径,了解分布式系统中不同组件之间的相互作用和性能延迟。
4.事件管理:捕获和处理系统中的事件,如警报、通知和异常情况。
5.可视化:通过仪表板、图表和可视化工具,将系统和应用程序的指标、日志和事件以可视化的方式展示出来。
Authing 基于对上述理念的理解,在公用云部署架构、私有化部署架构中都进行了考虑和设计,通过 Tracing、Metrics、Logging 的采集,进行事件管控,并及时将变更推送到客户端、服务端,从而启动相关策略的变化。此外,可视化报表大屏可帮助客户持续、及时地了解到一线的系统可用性指标情况、认证链路追踪、系统性能指标变化等,从而做到“心知肚明”,“及时响应”。
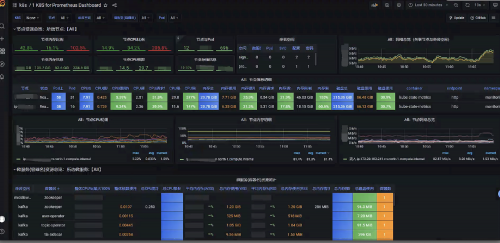
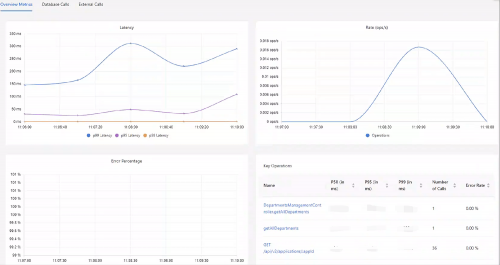
微服务治理
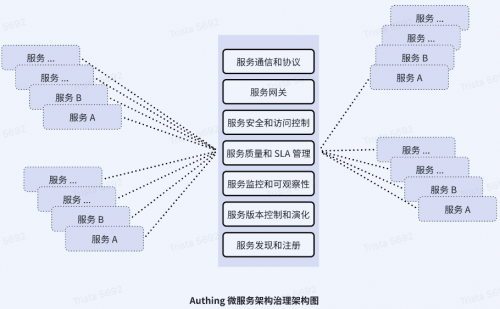
微服务治理(Microservices Governance)是指在微服务架构中对微服务进行管理和控制的一系列实践和策略。由于微服务架构的复杂性和分布式特性,需要一种有效的方式来确保微服务系统的可靠性、可扩展性和一致性。重要要考虑以下方面:
1.服务发现和注册:可以帮助服务在集群中自动注册和发现其他服务,并提供负载均衡和故障转移的能力。
2.服务通信和协议:需要定义和管理服务之间的通信协议、消息格式和接口规范,以确保服务之间的互操作性和一致性。
3.服务网关:服务网关是微服务架构中的入口点,可以提供统一的访问接口和安全性保护,并隔离客户端与后端微服务之间的直接通信。
4.服务监控和可观测性:通过监控指标、日志和分布式追踪等工具,可以实现对微服务的实时监控和故障排查。
5.服务安全和访问控制:包括身份验证、授权、数据加密和审计等安全措施,以保护服务免受恶意访问和攻击。
6.服务版本控制和演化:需要管理服务的版本控制、发布策略和回退计划,以确保服务的无缝演化和兼容性。
7.服务质量和 SLA 管理:包括定义和监测服务的性能、可用性和可靠性等指标,并确保满足业务需求和用户期望。
微服务治理是一个主流且较为成熟服务治理领域,Authing 也是按照上述的核心点进行具体的服务治理落地;但由于各个业务系统对微服务治理的需求和期望各有不同,这里不再具体阐述。
阿里云全球故障事件带来的巨大影响,又一次给行业的从业者、系统设计人员、企业服务采购者敲了警钟。虽然官方并未公布其故障背后的原因,但认证服务,作为最基础的门户安全服务,其 SLA 的高保证能最大程度避免这样的“全线”、“全球性”故障。本文通过“防治结合”的理念详细阐述了如何在认证服务领域,通过事件驱动设计理念、云中立理念、异地多活的措施、可观测性的提升、微服务治理的策略等具体方式提高系统的可用性、为用户承诺最高水平的 SLA。其设计理念也可以应用到其他服务领域。在具体落地时,还需要考虑具体 SLA 需求和成本的平衡,最终实现业务场景驱动技术迭代,技术迭代促进和保障业务场景。
作者:
潘娟,Apache Member & Incubator Mentor,Apache ShardingSphere PMC,AWS Data Hero,中国木兰开源社区导师,腾讯云 TVP。曾负责京东数科数据库智能平台的设计与研发,现专注于分布式数据库 & 中间件生态及开源领域。被评为《2020 中国开源先锋人物》,2021 OSCAR 尖峰开源人物。CSDN 2021 年度 IT 领军人物,2022 年在 ICDE 发表论文 “Apache ShardingSphere:A Holistic and Pluggable Platform for Data Sharding”。
相关新闻
◎版权作品,未经中国消费商网书面授权,严禁转载,违者将被追究法律责任。
Copyright 2013-2019. 中国消费商网 www.xiaofeishang.org All rights reserved.
违法和不良信息举报邮箱:jubao@xiaofeishang.org 执行主编:刘可





